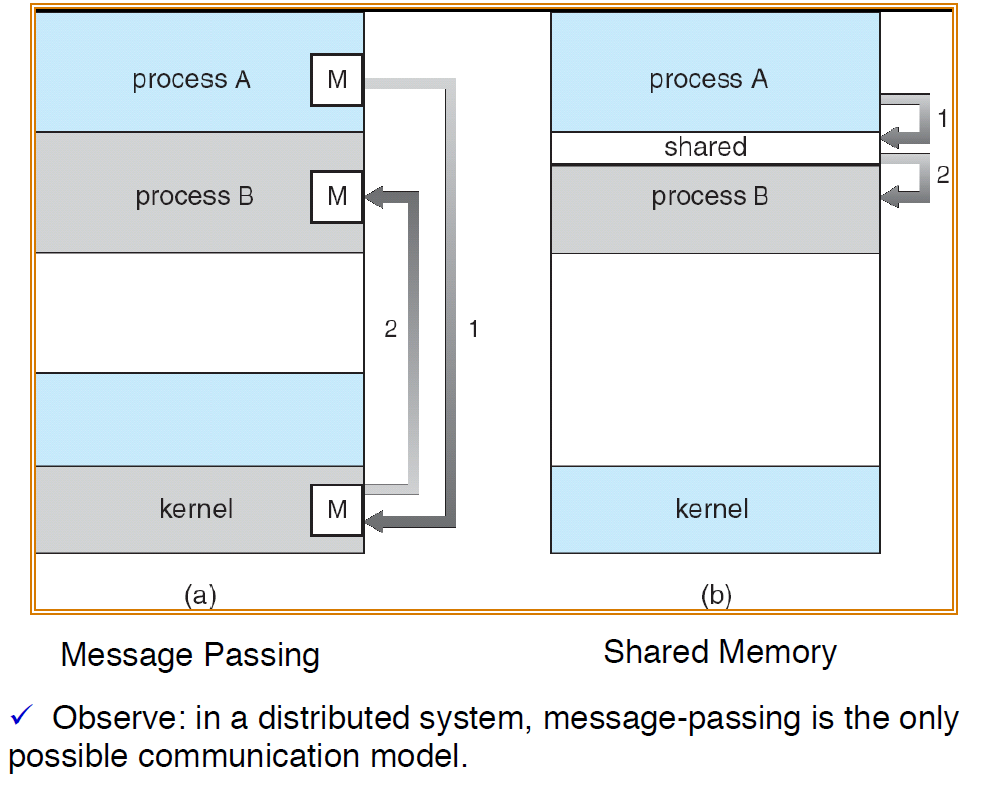
1. Concurrent access to shared data
- Example
- suppose that two processes A and B have access to a shared variable “Balance”
- process A: Balance = Balance – 100
- process B: Balance = Balance – 200
- Further, assume that Process A and Process B are executing concurrently in a time-shared, multiprogrammed system
- The statement “balance = balance – 100” is implemented by several machine level instructions such as
- A1. LOAD R1, BALANCE //load BALANCE from memory to register 1 (R1)
- A2. SUB R1, 100 //subtract 100 from R1
- A2. STORE BALANCE, R1 //store R1’s contents back to the memory location of BALANCE
- Similarly, “BALANCE = BALANCE – 200” can be implemented in the following
- B1. LOAD R1, BALANCE
- B2. SUB R1, 200
- B3. STORE BALANCE, R1
2. Race Condition
- Observe: in a time-shared system, the exact instruction execution order cannot be predicted
- Situations like this, where multiple processes are writing or reading some shared data and the final result depends on who runs precisely when, are called race conditions.
- A serious problem for any concurrent system using shared variables.
- We must make sure that some high-level code sections are executed atomically.
- Atomic operation means that it completes in its entirety without worrying about interruption by an other potentially conflict-causing process.
3. The Critical-Section Problem
- n processes are competing to use some shared data
- Each process has a code segment, called critical section (critical region), in which the shared data is accessed.
- Problem: ensure that when one process is executing in its critical section, no other process is allowed to execute in that critical section.
- The execution of the critical sections by the processes must be mutually exclusive in time
4. Solving Critical-Section Problem
Any solution to the problem must satisfy four conditions
- Mutual Exclusion
- no two processes may be simultaneously inside the same critical section
- Bounded Waiting
- no process should have to wait forever to enter a critical section
- Progress
- no process executing a code segment unrelated to a given critical section can block another process trying to enter the same crtical section
- Arbitrary speed
- no assumption can be made about the relative speed of different processes (though all processes have a non-zero speed)
5. General Structure of a Typical Process
do{
…
entry section
critical section
exit section
remainder section
} while(1);
- we assume this structure when evaluating possible solutions to Critical Section Problem
- in the entry section, the process requests “permission”
- we consider single-processor systems
5. Getting help from hardware
- one solution supported by hardware may be to use interrupt capability
do{
DISABLE INTERRUPTS
critical section;
ENABLE INTERRUPTS
remainder section
} while(1);
6. Synchronization Hardware
- Many machines provide special hardware instructions that help to achieve mutual exclusion
- The TestAndSet (TAS) instruction tests and modifies the content of a memory word automatically
- TAS R1, LOCK
- reads the contents of the memory workd LOCK into register R!
- and stores a nonzero value (e.g. 1) at the memory word LOCK (again, automatically)
- assume LOCK = 0;
- calling TAS R1, LOCK will set R! to 0, and set LOCK to 1
- Assume lOCK = 1
- calling TAS R1 LOCK will set R1 to 1, and set LOCK to 1
7. Mutual Exclusion with Test-and-Set
- Initially, share memory word LOCK = 0;
- Process pi
do{
entry-section:
TAS R1, LOCK
CMP R1, #0
JNE entry_section //if not equal, jump to entry
critical section
MOVE LOCK, #0 //exit section
remainder section
} while(1);
8. Busy waiting and spin locks
- This approach is based on busy waiting: if the critical section is being used, waiting processes loop continuously at the entry point
- a binary lock variable that uses busy waiting is called “spin lock”
9. Semaphores
- Introduced by E.W. Dijkstra
- Motivation: avoid busy waiting by locking a process execution until some condition is satisfied
- Two operations are defined on a semaphore variable s
- wait(s): also called P(s) or down(s)
- signal(s): also called V(s) or up(s)
- We will assume that these are the only user-visible operations on a semaphore
10. Semaphore Operations
- Concurrently a semaphore has an integer value. This value is greater than or equal to 0
- wait(s)
- wait/block until s.value > 0 //executed atomatically
- a process executing the wait operation on a semaphore, with value 0 is blocked until the semaphore’s value become greater than 0
- signal(s)
- s.value++ //execute automatically
- If multiple processes are blocked on the same semaphore “s”, only one of them will be awakened when another process performs signal(s) operation
- Semaphore as a general synchronization tool: semaphores provide a general process synchronization mechanism beyond the “critical section” problem
11. Deadlocks and Starvation
- A set of processes are aid to be in a deadlock state when every process in the set is waiting for an even that can be caused by another process in the set
- A process that is forced to wait indefinitely in a synchronization program is said to be subject to starvation
- in some execution scenarios, that process does not make any progress
- deadlocks imply starvation, bu the reverse is not true
12. Classical problem of synchornization
- Produce-Consumer Program
- Readers-Writer Problem
- Dining-Philosophers Problem
- The solution will use only semaphores as synchronization tools and busy waiting is to be avoided.
13. Producer-Consumer Problem
- Problem
- The bounded-buffer producer-consumer problem assumes there is a buffer of size n
- The producer process puts items to the buffer area
- The consumer process consumes items from the buffer
- The producer and the consumer execute concurrently
- Make sure that
- the producer and the consumer do not access the buffer area and related variables at the same time
- no item is made available to the consumer if all the buffer slots are empty
- no slots in the buffer is made available to the producer if all the buffer slots are full
- Shared data
- semaphore full, empty, mutex
- Initially
- full = 0; //the number of full buffers
- empty = n; //the number of empty buffers
- mutex = 1; // semaphore controlling the access to the buffer pool
- Producer Process

14. Readers-Writers Problem
- Problem
- A data object( e.g. a file) is to be shared among several concurrent processes
- A write process must have exclusive access to the data object
- Multiple reader processes may access the shared data simultaneously without a problem
- Shared data
- semaphore mutex, wrt
- int readaccount
- Initially
- mutex = 1
- readcount = 0, wrt= 1
- Writer Process
15. Dining-Philosophers Problem
- Problem
- five phisolophers share a common circular table
- there are five chopsticks and a bowl of rice (in the middle)
- when a philosopher gets hungry, he tries to pick up the closest chopsticks
- a philosopher may pick up only one chopstick at a time, and he cannot pick up one that is already in use.
- when done, he puts down both of his chopsticks, one after the other.
- Shared Data
- Initially
- all semaphore values are 1
















 = average length of the n-th CPU burst
= average length of the n-th CPU burst = predicted value of the next CPU burst
= predicted value of the next CPU burst
 set to 1/2
set to 1/2





 are less than or equal to 1, each successive term has less weight than its predecessor
are less than or equal to 1, each successive term has less weight than its predecessor




 : time quantum 8 milliseconds
: time quantum 8 milliseconds : time quantum 16 milliseconds
: time quantum 16 milliseconds ; FCFS
; FCFS