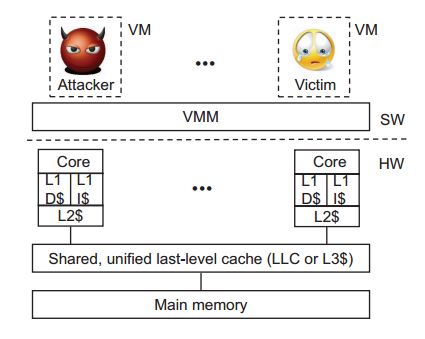
System Model for a Multi-core Processor
Cache Hierarchy
Reference [1]
Because of the long access time of main memory compared to fast processors, smaller but faster memory, called cache, are used to reduce the effective memory time as seen by a processor.
Modern processors feature a hierarchy of caches.
“Higher-level” caches, which are closer the processor core are smaller but faster than lower-level caches, which are closer to main memory.
L1 caches
Each core typically has two private top level caches
- 1) one for data
- 2) one for instructions
A typical L1 cache size is 32KB with 4-cycle access time, as in Intel Core and Xeon families.
LLC
The LLC is shared among all cores of a multicore chip and is a unified cache, i.e., it holds both data and instructions. [1]
LLC sizes measure in megabytes, and access latencies are of the order 40 cycles.
L2 caches
Modern X86 processors typically also support core-private, unified L2 caches of intermediate size and latency.
How it works
Any memory access first access the L1 cache, and on a miss, the request is sent down the hierarchy until it hits in a cache or accesses main memory.
The L1 is typically indexed by virtual address. While all other caches are indexed by physical address.
Cache Access
Reference [1]
To exploit spatial locality, caches are organized in fixed-size lines, which are the units of allocation and transfer down the cache hierarchy.
A typical line size B is 64bytes.
The log2B lowest-order bits of the address, called the line offset, are used to locate a datum in the cache line.
Set-associate
Caches today are usually set-associate, i.e., organized as S sets of W lines each, called a W-way set-associative cache. As shown in the following figure.[1]
When the cache is accessed, the set index field of the address, log2S consecutive bits starting from bit log2B is used to locate a cache set. The remaining high-order bits are used as a tag for each cache line.
After locating the cache set, the tag field of the address is matched against the tag of the W lines in the set to identify if one of the cache line is a cache hit.
Cache Replacement
As memory is much larger than the cache, more than W memory lines may map to the same cache set, potentially resulting in cache contention. If an access misses in the cache, and all lines of the matching set are in use, one cache line must be evicted to free cache slot for the new cache line being fetched from the next level of cache or from main memory for the LLC. The cache’s replacement policy determines the line to evict. Typically replacement policies are approximations to least-recently-used (LRU). [1]
 |
| Traditional Cache |
Per-Core Slice Cache
[1] Modern Intel processors, starting with the Sandy Bridge microarchitecture, use a more complex architecture for the LLC, to improve its performance.
The LLC is divided into pre-core slices, which are connected by a ring bus. Slices can be accessed concurrently and are effective separate caches, although the bus ensures that each core can access the full LLC (with higher latency for remote slices).
 |
| Sliced Cache |
 |
| Ring bus architecture and sliced LLC |
Reference
[1] Last-Level Cache Side-Channel Attacks are Practical, by Fangfei Liu et al, in Security&Privacy 2015